How to create a RAG application using .NET Aspire, Ollama, and Semantic Kernel?
I have been planning this now for a while and now I had time to investigate and explore this topic a bit more. In this blog post, I'll show how to create a .NET Aspire-powered RAG application that hosts a chat user interface, API, and Ollama container with a pre-downloaded Phi language model. The purpose is to test the usage of local small language models, Semantic Kernel, and learn how to make this happen with .NET Aspire (preview 6).
In a high-level totality looks like this:
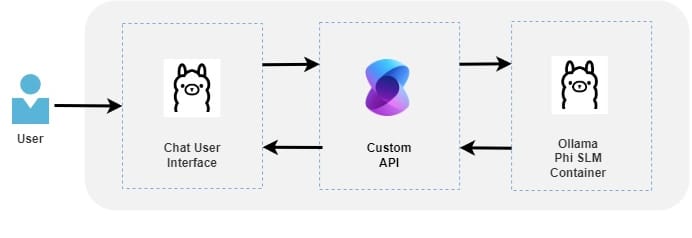
Before starting let's go first through the key terminologies used in this blog post.
Key terminology
.NET Aspire
.NET Aspire is designed to improve the experience of building .NET cloud-native apps. It provides a consistent, opinionated set of tools and patterns that help you build and run distributed apps.
Sources: Aspire overview
Small language model (SLM)
A Small Language Model (SLM) is a compact AI model that uses a smaller neural network, fewer parameters, and less training data than larger language models. SLMs are designed for efficiency and faster training times. SLMs are smaller versions of their LLM (large language model) counterparts. There are multiple SLM models in the market and Phi-3 is one of them.
Sources: What is a Small Language Model?, Introducing Phi-3: Redefining what’s possible with SLMs
Retrieval Augmented Generation (RAG)
As we know language models provide generic answers based on the training data. This means that the language model cannot provide accurate answers related to an organization or product if that information is not part of the trained model.
RAG is a powerful technique for improving and optimizing the output of a language model by integrating applications with relevant data sources. RAG extends the already powerful capabilities of LLMs to specific domains or an organization's internal knowledge base without retraining the model.
Sources: What is Retrieval-Augmented Generation?
Ollama
Ollama is an open-source application that allows you to run language models locally. Can be said that Ollama is a bridge between the language model and your application. Ollama provides an OpenAI-compatible API to enable communication between your application and language models.
Sources: Ollama, OpenAI API compatibility
Semantic Kernel (SK)
Semantic Kernel (SK) is a lightweight and open-sourced SDK that enables developers to create powerful AI solutions by integrating language models with conventional programming languages like C# and Python. Basically, SK acts as an orchestration layer between AI models and your application. Semantic Kernel has powerful features that enable you to integrate your application into existing services and data sources and utilize to power of the language models. Currently, SK supports models from OpenAI, including GPT-4, and Azure OpenAI Service.
Sources: What is Semantic Kernel?, Hello, Semantic Kernel!
Application Overview
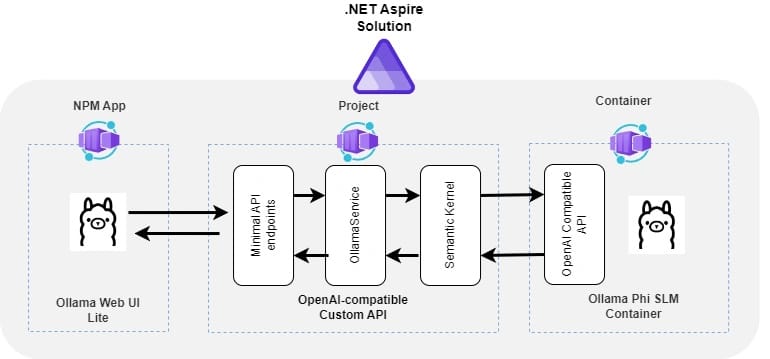
Solution has three main components:
1. Ollama Web UI Lite Chat User Interface
I didn't want to spend time building the chat user interface so I decided to use Ollama Web UI Lite which is a streamlined, simplified, and more compact version of Ollama Web UI. Ollama Web UI provides a complete user interface and solution that communicates with OpenAI-compatible API.
2. OpenAI-compatible Custom API
Ollama Web UI can be integrated directly with Ollama container's built-in OpenAI-compatible API. Instead of doing that, the purpose is to create an own custom OpenAI-compatible API between UI and Ollama Container. This custom API utilizes Semantic Kernel to communicate with Ollama container's OpenAI API endpoint. The next blog post will cover the handling of Semantic Kernel's plugins.
3. Ollama Phi SLM Container
This sample solution uses an image provided by langchain4j which contains the Ollama and pre-downloaded Phi small language model. As said earlier, Ollama provides by default built-in OpenAI-compatible API which will be used from our custom API using Semantic Kernel.
Setting up the .NET Aspire solution
Application Host project
In .NET Aspire, the Application Host Project, also known as the Orchestrator Project, is a .NET project that orchestrates the app model. It is responsible for running all of the projects that are part of the .NET Aspire application.
This configuration adds Ollama container with pre-downloaded Phi LLM, Ollama Web UI Lite chat user interface, and OpenAI-compatible custom API to the .NET Aspire solution.
var builder = DistributedApplication.CreateBuilder(args);
// Ollama Phi SLM Container
// * By default, Ollama container exposes OpenAI API in port 11434. This configuration changes the port to 7876.
var ollama = builder.AddContainer("ollama", "langchain4j/ollama-phi")
.WithVolume("/root/.ollama")
.WithBindMount("./ollamaconfig", "/root/")
.WithHttpEndpoint(port: 7876, targetPort: 11434, name: "OllamaOpenApiEndpointUri")
.WithContainerRunArgs("--gpus=all");
var ollamaOpenApiEndpointUri = ollama.GetEndpoint("OllamaOpenApiEndpointUri");
// Ollama Web UI Lite Chat User Interface
// * Aspire.Hosting.NodeJs must be installed to enable adding Npm applications to the solution.
// * Copy Ollama Web UI Lite's files and folders from Github to the folder (/OllamWebUi) under the solution.
builder.AddNpmApp("ollamawebui", "../OllamWebUi", "dev")
.WithEnvironment("BROWSER", "none")
.WithExternalHttpEndpoints();
// OpenAI-compatible Custom API
// * Semantic Kernel needs the Ollama container's OpenAI API endpoint url
builder.AddProject<Projects.Aspire_OpenAI_Api>("openai-api")
.WithEnvironment("OllamaOpenApiEndpointUri", ollamaOpenApiEndpointUri);
builder.Build().Run();OpenAI-compatible Custom API
As said this custom API serves the data for Ollama Web UI and utilizes the Semantic Kernel to communicate with local Ollama service.
Program.cs configuration
Install Microsoft.SemanticKernel NuGet package and add Kernel to the Dependency Injection.
var builder = WebApplication.CreateBuilder(args);
builder.AddServiceDefaults();
builder.Services.AddEndpointsApiExplorer();
builder.Services.AddSwaggerGen();
var ollamaOpenApiEndpoint = builder.Configuration["OllamaOpenApiEndpointUri"];
if(!string.IsNullOrEmpty(ollamaOpenApiEndpoint))
{
// Install Microsoft.SemanticKernel NuGet package and add Kernel to the Dependency Injection.
builder.Services
.AddKernel()
.AddOpenAIChatCompletion("phi", new Uri(ollamaOpenApiEndpoint), null);
}
builder.Services.AddScoped<IOllamaService, OllamaService>();
builder.Services.AddCors(options =>
{
options.AddPolicy("AllowAll", builder =>
{
builder.AllowAnyOrigin()
.AllowAnyHeader()
.AllowAnyMethod();
});
});
var app = builder.Build();
app.UseCors("AllowAll");
app.MapDefaultEndpoints();
if (app.Environment.IsDevelopment())
{
app.UseSwagger();
app.UseSwaggerUI();
}
app.UseHttpsRedirection();
// Register Minimal API endpoints
app.RegisterOllamaEndpoints();
app.Run();OllamaService
OllamaService is a wrapper service that abstracts the Semantic Kernel. In this sample, GetStreamingChatMessageContentsAsync method is used to return messages as a stream. Response is constructed as a complete sentence that is returned to the front end.
public interface IOllamaService
{
Task<Dictionary<int, ChatResponse>> GetStreamingChatMessageContentsAsync(ChatRequest request);
Task<string> GetChatMessageContentAsync(string prompt);
}
public class OllamaService: IOllamaService
{
private Kernel _kernel;
private IChatCompletionService _chatCompletionService;
public OllamaService(Kernel kernel)
{
_kernel = kernel;
_chatCompletionService = _kernel.GetRequiredService<IChatCompletionService>();
}
/// <summary>
/// Get a single chat message content for the prompt and settings.
/// </summary>
public async Task<string> GetChatMessageContentAsync(string prompt)
{
var aiData = await _chatCompletionService.GetChatMessageContentAsync(prompt);
return aiData.ToString();
}
/// <summary>
/// Get streaming chat contents for the chat history provided using the specified settings.
/// </summary>
public async Task<Dictionary<int, ChatResponse>> GetStreamingChatMessageContentsAsync(ChatRequest request)
{
var chat = PrepareChatHistory(request);
var aiData = _chatCompletionService.GetStreamingChatMessageContentsAsync(chat, kernel: _kernel);
Dictionary<int, ChatResponse> chatResponses = [];
// Gather the full sentences of response
await foreach (var result in aiData)
{
chatResponses.TryGetValue(result.ChoiceIndex, out ChatResponse chatResponse);
if (chatResponse == null)
{
chatResponses[result.ChoiceIndex] = new ChatResponse()
{
model = result?.ModelId,
created_at = result?.Metadata["Created"].ToString(),
message = new Message()
{
content = result?.Content,
role = result?.Role.ToString()
}
};
}
else
{
chatResponse.message.content += result.Content;
}
}
return chatResponses;
}
private ChatHistory PrepareChatHistory(ChatRequest request)
{
ChatHistory chat = new("Hello!");
if (request?.messages != null)
{
foreach (var item in request.messages)
{
var role = item.role == "user" ? AuthorRole.User : AuthorRole.Assistant;
chat.AddMessage(role, item.content);
}
}
return chat;
}
}Needed API endpoints
Ollama Web UI needs a few endpoints that provide information about the version number, available language models, chat title, and of course LLM generated answers for the front end.
GET /tags endpoint
Ollama Web UI enables one to choose which language model to use. The tags endpoint returns a list of language models that can be used. In this example, we used a hard-coded phi-2 model.
endpoints.MapGet("/api/tags", () => new
{
models = new[] {
new
{
name = "phi:latest",
model = "phi:latest",
modified_at = DateTime.UtcNow,
size = 1602463378,
digest = "e2fd6321a5fe6bb3ac8a4e6f1cf04477fd2dea2924cf53237a995387e152ee9c",
details = new
{
parent_model = "",
format = "gguf",
family = "phi2",
families = new[] { "phi2" },
parameter_size = "3B",
quantization_level = "Q4_0"
}
}
}
}).WithName("Tags");GET /version endpoint
The version endpoint returns the version of the Ollama.
endpoints.MapGet("/api/version", () => new
{
version = "0.1.32"
}).WithName("Version");POST /generate endpoint
The generate endpoint generates a short title for a chat conversation that is shown in the chat history.
endpoints.MapPost("/api/generate", async (HttpContext httpContext, IOllamaService ollamaService) =>
{
var request = httpContext.GetRequestBody<GenerateRequest>();
var response = await ollamaService.GetChatMessageContentAsync(request.prompt);
return new
{
response
};
}).WithName("Generate");The endpoint receives this kind of request model from the front end.
{
"model": "phi:latest",
"prompt": "Generate a brief 3-5 word title for this question, excluding the term 'title.' Then, please reply with only the title: What is the capital of Finland?",
"stream": false
}POST /chat endpoint
The chat endpoint is the most important one to provide answers generated by LLM for the front end. The front end sends this kind of request model to the back end:
{
"model": "phi:latest",
"messages": [
{
"role": "user",
"content": "What is the capital of Finland?"
},
{
"role": "assistant",
"content": ""
}
],
"options": {}
}Ollama Web UI Lite uses text/event-stream content type when requesting chat completion data from the back-end API. This indicates to the client that it’s an SSE (Server-Sent Events) response. A Server-Sent Event is a way for a server to stream data to the browser. Roko Kovač has written a good article about Server-Sent events in .NET and I recommend you to read it.
The actual API endpoint utilizes OllamaService to get the data via Semantic Kernel.
endpoints.MapPost("/api/chat", async Task (HttpContext httpContext, IOllamaService ollamaservice, CancellationToken ct) =>
{
httpContext.Response.Headers.Add("Content-Type", "text/event-stream");
var request = httpContext.GetRequestBody<ChatRequest>();
var responses = await ollamaservice.GetStreamingChatMessageContentsAsync(request);
foreach (var response in responses.Values)
{
// Server-Sent Events
var sseMessage = $"{JsonSerializer.Serialize(response)}";
await httpContext.Response.Body.WriteAsync(Encoding.UTF8.GetBytes(sseMessage));
await httpContext.Response.Body.FlushAsync();
}
}).WithName("ChatCompletion");The response model returned back to the front end:
{
"model": "phi",
"created_at": "10.5.2024 8.55.09",
"message": {
"role": "assistant",
"content": " The capital of Finland is Helsinki.\n"
},
"done": false,
"total_duration": 0,
"load_duration": 0,
"prompt_eval_count": 0,
"prompt_eval_duration": 0,
"eval_count": 0,
"eval_duration": 0
}Ollama Web UI Lite
When the solution is up and running you can change the API address to point to our custom API from the Ollama Web UI settings.
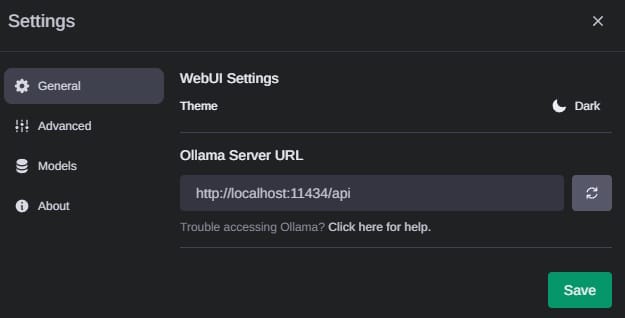
Now everything is ready for testing :)
Summary
This was an interesting experience to test and learn more about language models and how to run them locally. Aspire is also a great match and convenient when hosting this kind of containerized service.
In the next blog post, I'll integrate Semantic Kernel plugins into this existing solution so stay tuned.
Comments